In diesem Blogartikel erkläre ich ein wenig, wie die Controller-Cluster in ArubaOS 8.x funktionieren, wie man sie einrichtet und welche Funktionen sie bieten. Alle Erklärungen und Tests habe ich mit zwei Aruba 7005 Controllern, drei AP215 und einem Mobility-Master auf ArubaOS Version 8.2.0.1 durchgeführt.
Was ist ein Controller-Cluster in ArubaOS 8.x?
Ein Controller-Cluster ist, wie der Name schon sagt, ein Zusammenschluss von mehreren Controllern. Sie arbeiten in diesem Setup als reine Slaves und bekommen ihre komplette Konfiguration vom Mobility-Master. Dieser ist in meinem Fall eine virtuelle Maschine, über welche man die komplette Konfiguration seines Netzwerkes verwalten kann. Wenn man das Master-Local Setup aus ArubaOS 6.5 mit der neuen Cluster-Architektur vergleicht, hat sich einiges geändert. Beispielsweise findet in einem gewissen Rahmen ein Load-Balancing der User und des Traffics statt und es gibt eine Option für eine Redundanz innerhalb des Clusters. Für eben diese Redundanz aktiviert man diese in den Einstellungen und konfiguriert eine VRRP-IP auf jeden Cluster-Node. Zwar benötigen die APs diese IP nur beim Starten, allerdings kann man hierdurch erreichen, dass die APs immer ihren Controller finden, auch wenn eines der Cluster-Member mal down sein sollte.
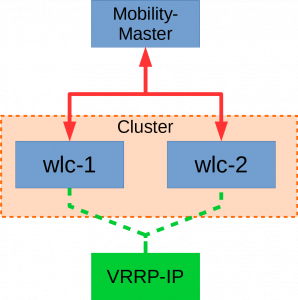
Zu sehen ist der Aufbau meines Test-Clusters. Die beiden WLAN-Controller kommunizieren mit dem Mobility-Master. Das Cluster (orange unterlegt) hat eine gemeinsame VRRP-IP (grün).
Hinzufügen von Controllern in ein Cluster
Bevor man Controller in ein Cluster hinzufügen kann, muss man ein Cluster-Profil erstellen. Hierzu logged man sich per SSH auf dem Mobility-Master ein.
(mobilitymaster) [mynode] #cd /md/
(mobilitymaster) [md] #configure terminal
Enter Configuration commands, one per line. End with CNTL/Z(mobilitymaster) [md] (config) #lc-cluster group-profile Test-Cluster
(mobilitymaster) ^[md] (Classic Controller Cluster Profile „Test-Cluster“) #controller 129.13.64.75 mcast-vlan 1370
(mobilitymaster) ^[md] (Classic Controller Cluster Profile „Test-Cluster“) #controller 129.13.64.76 mcast-vlan 1370
(mobilitymaster) ^[md] (Classic Controller Cluster Profile „Test-Cluster“) #redundancy
(mobilitymaster) ^[md] (Classic Controller Cluster Profile „Test-Cluster“) #exit
(mobilitymaster) ^[md] (config) #write memory
Mit dem Befehl „lc-cluster group-profile <Name>“ legt man ein neues Cluster-Profil an. Zu diesem fügt man dann die beiden Controller hinzu. Hierzu verwendet man die „Controller-IP“. Als Multicast-VLAN habe ich das VLAN genommen, in dem die beiden Controller ihre IPs haben. Am Ende schaltet man noch Redundanz ein und speichert die Konfiguration. Nun muss man noch den einzelnen Controllern mitteilen, dass sie Teil eines Clusters sind:
(mobilitymaster) [md] (config) #cd aruba7005-01
(mobilitymaster) [00:0b:86:be:bb:f8] (config) #lc-cluster group-membership Test-Cluster
(mobilitymaster) ^[00:0b:86:be:bb:f8] (config) #cd aruba7005-02
(mobilitymaster) ^[00:0b:86:be:ba:c0] (config) #lc-cluster group-membership Test-Cluster
(mobilitymaster) ^[00:0b:86:be:ba:c0] (config) #cd /md(mobilitymaster) ^[md] (config) #write memory
Nun sind die Controller in einem Cluster und man kann beginnen VRRP zwischen den beiden Controllern zu konfigurieren.
Virtuelle Cluster-IP mit VRRP konfigurieren
Die „virtuelle Cluster-IP“, wie sie gerne genannt wird, ist in Wirklichkeit einfach nur eine VRRP-Adresse. Für die Funktion des Clusters hat sie keinen direkten Sinn, lediglich wird sie wichtig, wenn APs booten und ihren Master-Controller kontaktieren wollen. Wenn der AP als Master eine Management-IP hätte und der Controller down wäre, so würde er nicht booten. Wenn wir nun aber eine IP-Adresse eintragen, die VRRP benutzt, so finden die APs immer ihren Master.
(mobilitymaster) [md] (config) #cd aruba7005-01
(mobilitymaster) [00:0b:86:be:bb:f8] (config) #vrrp 1
(mobilitymaster) ^[00:0b:86:be:bb:f8] (config-submode)#description aruba-cluster
(mobilitymaster) ^[00:0b:86:be:bb:f8] (config-submode)#authentication <password>
(mobilitymaster) ^[00:0b:86:be:bb:f8] (config-submode)#ip address 129.13.64.77
(mobilitymaster) ^[00:0b:86:be:bb:f8] (config-submode)#priority 200
(mobilitymaster) ^[00:0b:86:be:bb:f8] (config-submode)#vlan 1370
(mobilitymaster) ^[00:0b:86:be:bb:f8] (config-submode)#exit
(mobilitymaster) ^[00:0b:86:be:bb:f8] (config) #write memory
Die Konfiguration ist bei beiden Controllern die gleiche. Wichtig ist, dass man einem der beiden Controller eine höhere Priorität als dem anderen gibt, damit dieser immer bevorzugt wird und nur im Fehlerfall der andere Controller reagiert.
Seamless-Failover und wie es funktioniert
Wenn man nun im Webinterface auf das Cluster-Dashboard schaut, kann man sehen, wie die aktuelle Auslastung des Clusters ist und wie viele APs auf den Controllern terminieren.
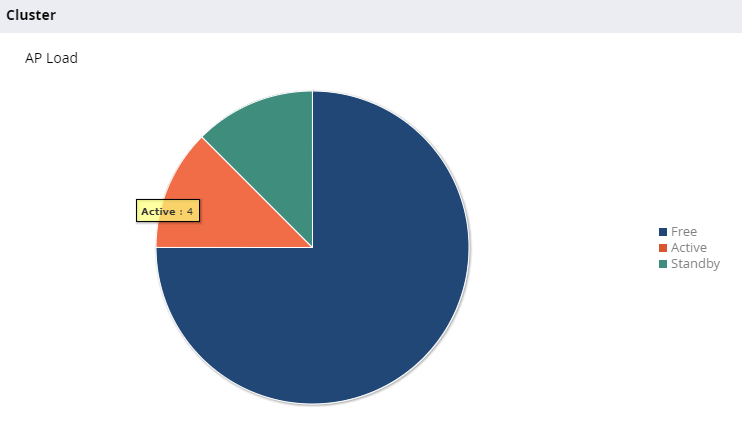
Auslastung des Test-Clusters
Zu erkennen ist, dass vier aktive und vier passive APs auf dem Cluster terminieren. Habe ich also insgesamt acht APs auf dem Cluster? Nein. Die APs bauen lediglich mehrere Tunnel zu dem Cluster auf. Einen aktiven und einen fallback Tunnel. Dies haben wir durch das Aktivieren der Option „Redundancy“ im Controller-Cluster-Profil erreicht. Bei den Usern passiert das gleiche. Die Tunnel, durch die der Traffic zu den Controllern läuft, werden zu mehreren Controllern aufgebaut.
Mit einem redundanten Cluster kann man von einem Feature namens „Seamless-Failover“ profitieren. Dies bedeutet, dass im Fehlerfall der WLAN-User nicht mitbekommt, dass gerade der Controller, durch den sein Traffic lief, ausgefallen ist. Hierzu werden sämtliche Sessions permanent zwischen dem primären und sekundären Controller synchronisiert. Wenn nun also ein Controller wegbricht findet ein nahtloser Wechsel statt und es gehen keine Verbindungen kaputt.
Ich habe dieses Feature wie in einem richtigen Fehlerfall getestet. Ich habe mein Laptop ins WLAN gehängt, einen Ping gestartet, nachgeschaut auf welchem Controller meine Verbindung terminiert und genau von diesem Controller den Uplink gezogen. Leider verlor ich die Verbindung zum WLAN, da der AP seinen Controller verlor und hatte erst nach 30 Sekunden wieder eine Verbindung.
Nachdem ich mir die Sache mit meinen Systems Engineer angeschaut habe wurde folgendes klar: Das Seamless-Failover funktioniert nur, wenn das Cluster in einem Zustand namens „L2-Connected“ ist. Dies bedeutet, dass alle VLANs, welche auf den Controllern konfiguriert sind auch durchgängig sein müssen. Um dies zu überprüfen, senden die Controller spezielle Broadcast-Frames in jedes VLAN, welches auf ihnen Konfiguriert ist und schauen, ob es bei den anderen Controllern ankommt. Da auf dem Switch, an dem die Controller hängen, kein VLAN 1 konfiguriert ist, waren die Controller auch nicht in der Lage sich durch dieses VLAN zu sehen. Welchen Zustand das Cluster hat und welches VLAN nicht durchgängig ist kann man wie folgt überprüfen:
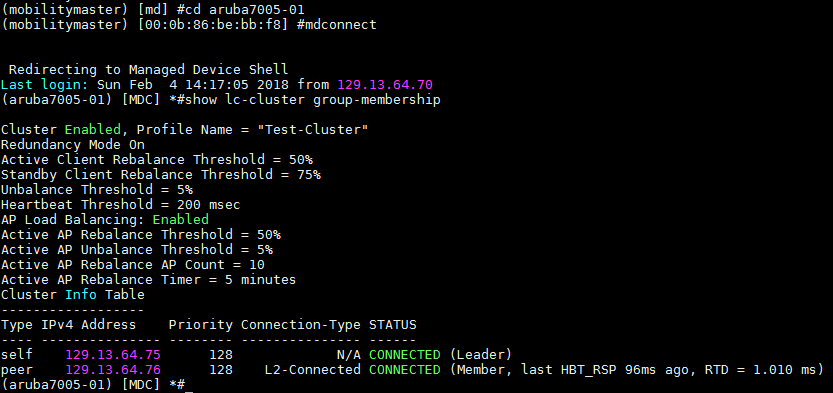
Zustand des Clusters aus Sicht des Controllers
Da man den Zustand des Clusters in der CLI nur von einem Controller abrufen kann verbinden wir uns mit dem Befehl „mdconnect“ auf einen der Controller. In der Spalte „Connection-Type“ sehen wir, dass der zweite Controller den Zustand „L2-Connected“ hat. Für den Fall, dass dem nicht so ist, kann man mit dem folgenden Befehl herausfinden, welches VLAN Probleme macht:

Status der VLAN-Probe
Leider kann man unter „VLAN_FAIL“ immer nur eine VLAN-ID sehen, weshalb man es immer nach und nach fixen muss. Falls man (wie in unserem Fall) eine VLAN-ID aus diesem Probing-Prozess ausschließen will, so kann man dies auf dem Mobility-Master auf den einzelnen Controllern mit dem Befehl „lc-cluster exclude-vlan <vlan-id>“ konfigurieren. Leider ist dieser Befehl etwas kaputt, da er jedes Mal die Liste der bereits ausgeschlossenen VLANs überschreibt und nur die VLANs des aktuellen Befehls übernimmt.
Fazit zum Controller-Clustering
Insgesamt funktioniert das Clustering, wenn man alles richtig konfiguriert hat, sehr gut. Ich habe mehrere Tests gemacht, bei denen ich Traffic durch das WLAN geschoben habe, den Uplink meines primary Controllers gezogen habe und aus User-Sicht nicht gemerkt habe, dass der Controller gerade weg war. Durch eben dieses Feature eröffnen sich neue Möglichkeiten, da man keine Wartungsfenster mehr braucht und durch andere Features sogar Live-Updates ohne Ausfälle machen kann. Es wird von manchen Herstellern immer Werbung gegen Controller-basierte Architekturen gemacht, weil man ja einen Single-Point-of-Failure hätte – spätestens mit diesem Feature sollte klar sein, dass dies nicht der Fall ist.
Pingback: buying rifaximin generic new zealand
Pingback: buy cheapest androxal online
Hallo Hendrik,
toller Artikel! DANKE! Ich selber steige gerade erst in die Aruba Wlan Welt ein. VRRP ist mir immer noch ein Rätsel. Muss ich in jedem SSID Vlan eine IP für VRRP vorsehen, wenn ich einen Cluster baue? Oder habe ich da etwas in deinem Artikel überlesen?
Vg
Michael
Hi Michael,
nein, die IP hier ist eine reine Management-IP, mit der die APs ihr Cluster finden. Die Clients werden normalerweise einfach am Controller in VLANs gebridged.